




一、背景
项目中使用中python识别图片中的文字,所以就有了下文
二、依赖环境
1.安装tesseract(我选择了最新的包)
安装包地址:
https://digi.bib.uni-mannheim.de/tesseract/
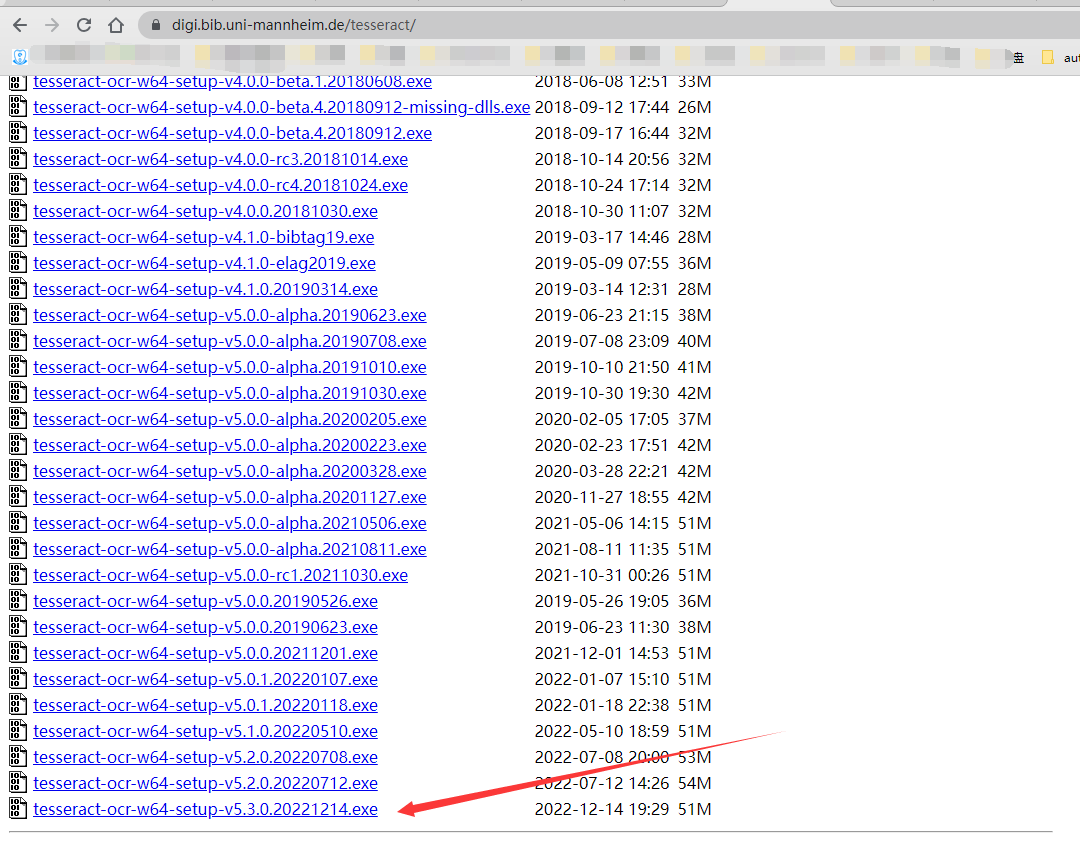
注意:记住安装路径后面会配置环境变量用到
2.安装中文语言包
安装包地址:
https://tesseract-ocr.github.io/tessdoc/Data-Files
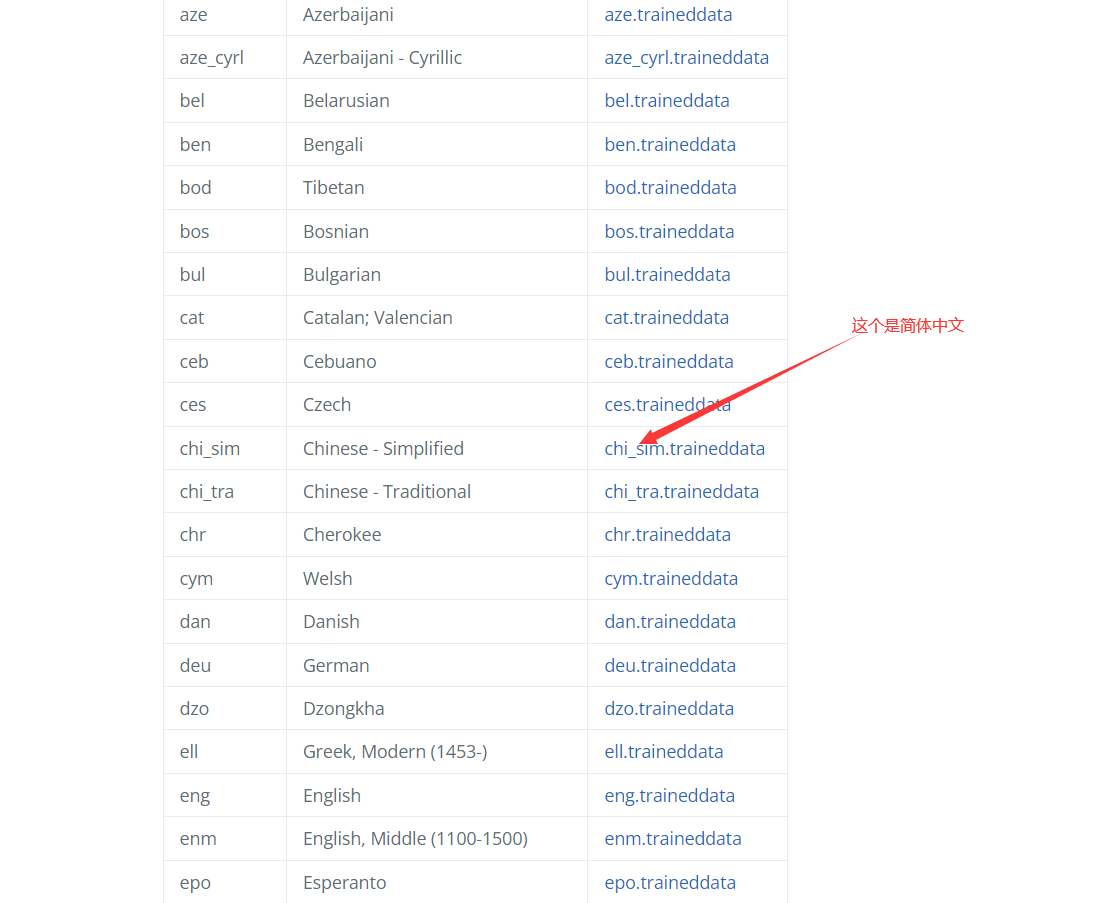
3.配置环境变量
添加用户变量:TESSDATA_PREFIX
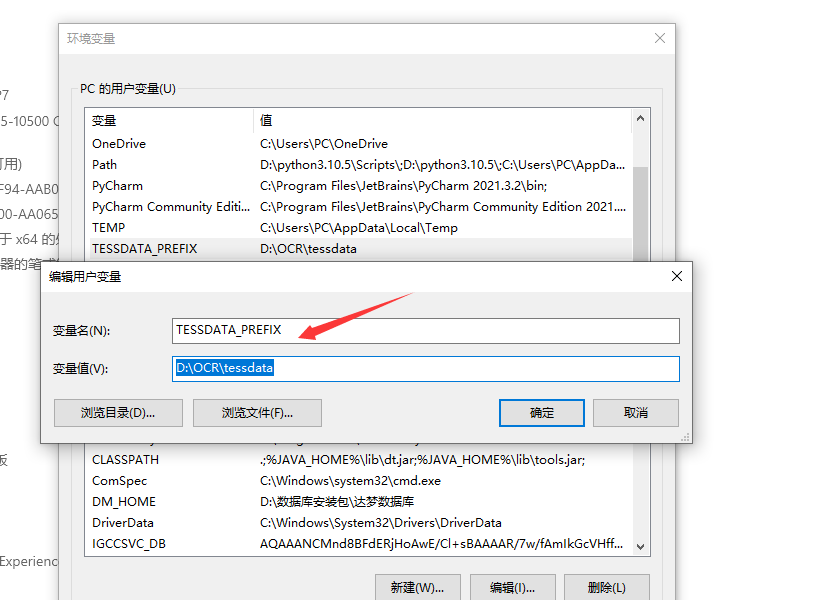
添加环境变量
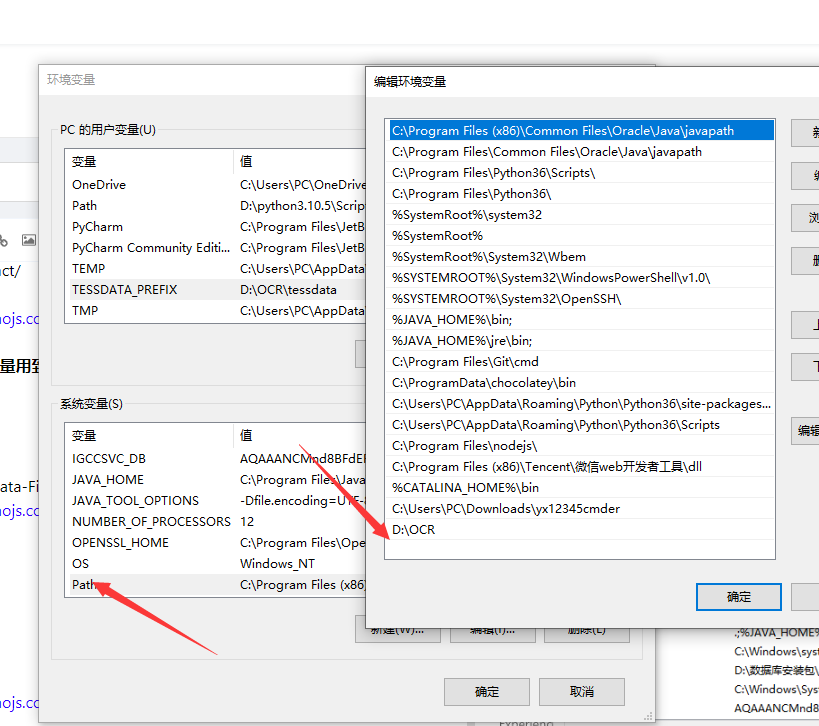
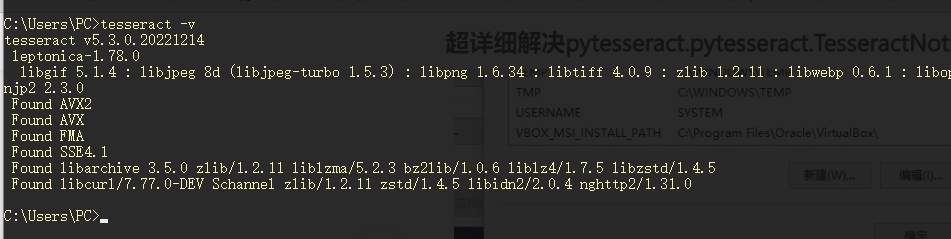
4.测试是否安装成功
终端执行tesseract -v
5.执行代码
# coding=utf-8
"""
@project: automation_tools
@Author:gaojs
@file: test043.py
@date:2023/7/17 15:07
@blogs: https://www.gaojs.com.cn
"""
import pytesseract
from PIL import Image
def get_text_from_photo(photo_path):
"""
从图片中获取文字
"""
# 读取图片
im = Image.open(photo_path)
# 识别文字,并指定语言
text = pytesseract.image_to_string(im, lang='chi_sim')
print(text)
return text
if __name__ == '__main__':
get_text_from_photo(photo_path='test043.png')
6.错误提示
pytesseract.pytesseract.TesseractNotFoundError: tesseract is not installed or it's not in your PATH. See README file for more information.
7.解决报错
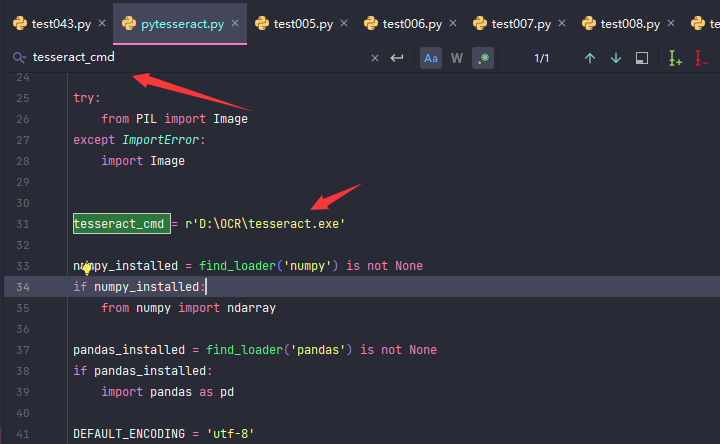
在pytesseract库下的pytesseract.py文件中找到tesseract_cmd = 'tesseract',修改成 tesseract_cmd =r'D:\OCR\tesseract.exe'
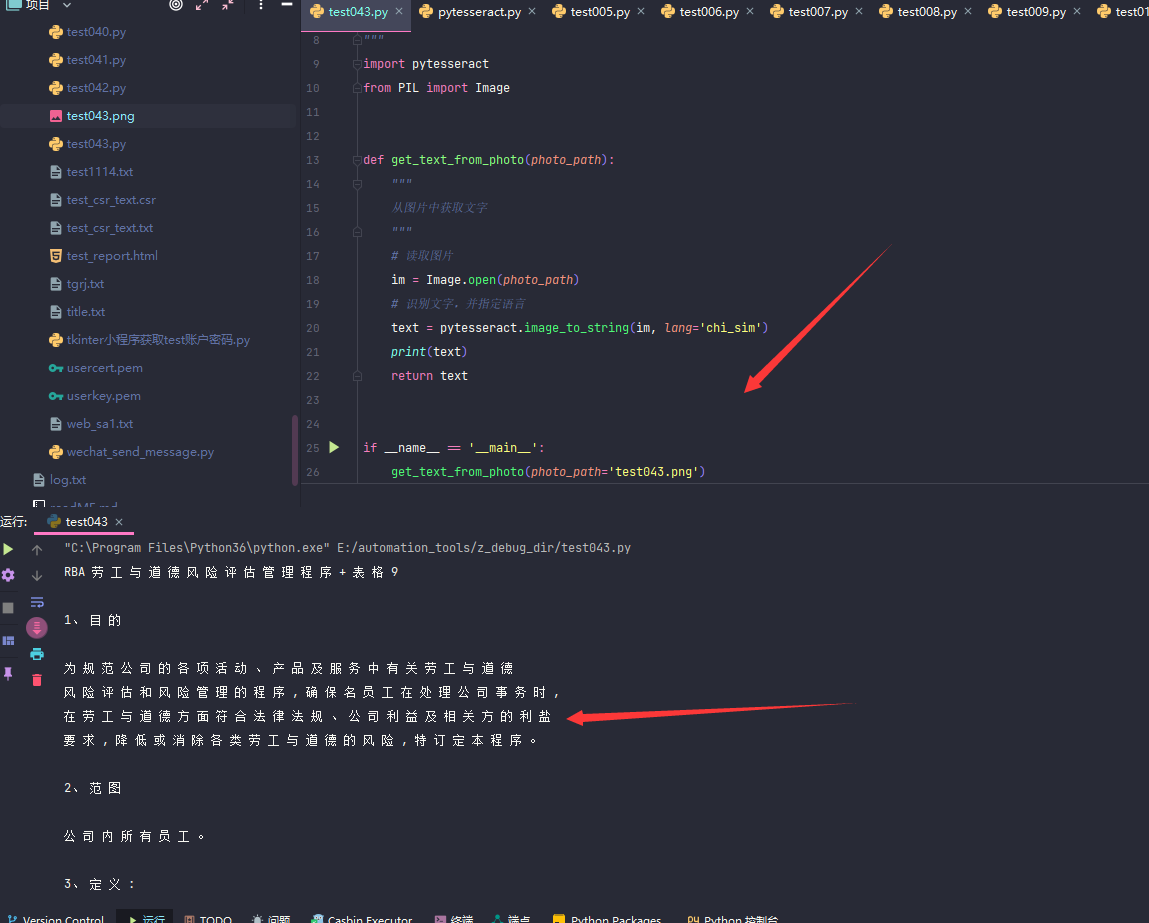
8.成功运行
评论区